考研视角下的C语言(上)
考研视角下的C语言(上)
当你想准备考研408,C语言就成了你绕不过去的专业课门槛,在考研中的复习C语言是复习408专业课的第一步, 区别于我们在大一学习的C语言,考研的C语言只需要学习到链表部分,但对在C语言的视角下对计算机的理解更加深入,以下内容仅适合有一些基础的同学,现将C语言重要知识点按照章节总结如下:
第一章_配置C语言开发环境
大一的时候应该配置过,我使用的是VS2022,具体配置与使用可参考如下文章。
https://blog.csdn.net/Daears/article/details/126359972 https://blog.csdn.net/2401_87692645/article/details/148870278
第二章_程序员视角中的计算机
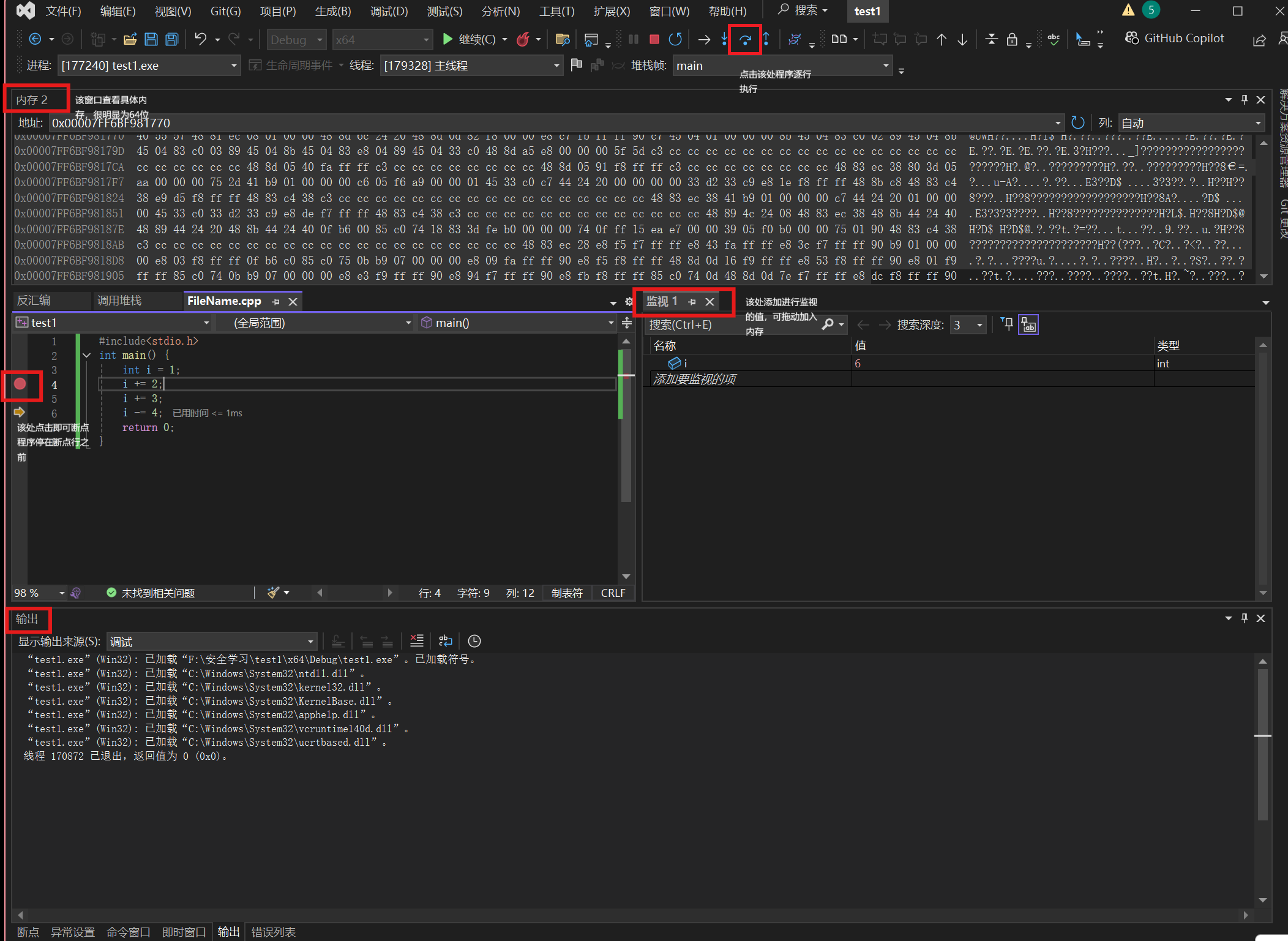
2.1 如何设置断点进行程序的调试
如图所示,只用保留这几个窗口即可(打断点后F5即可跳转调试界面,然后手动在 调试->窗口 中设置需要的窗口,比如图中的内存窗口),该技巧会在考研学习的过程中不断地用到。
2.2 内存模型
在程序员的视角中看计算机,无非就两个东西,CPU和存储器,接下来介绍一个非常重要的存储器–内存。
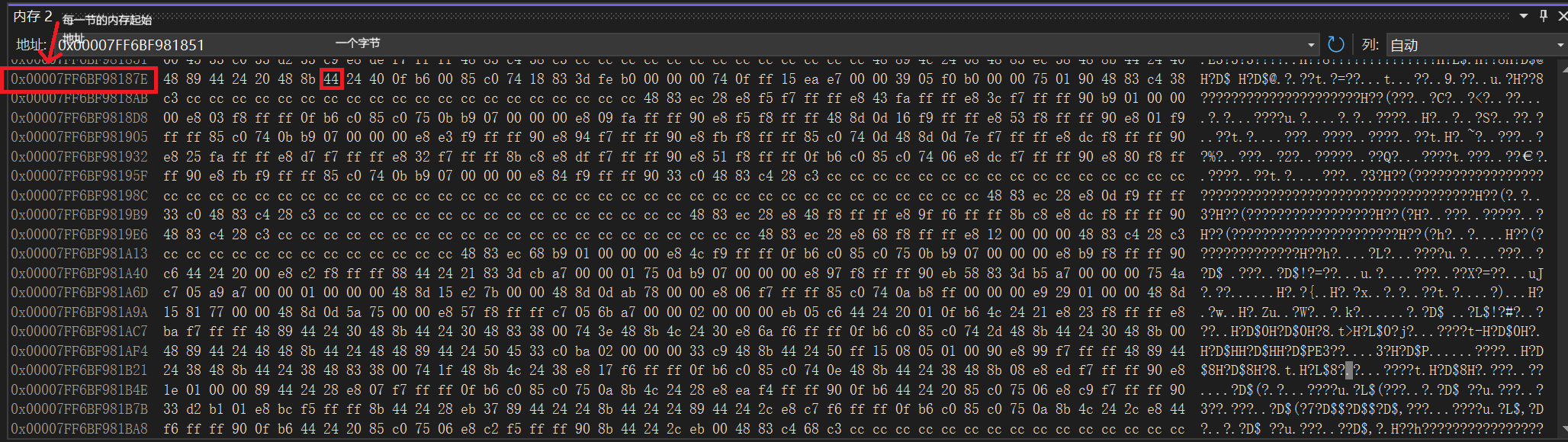
在vs2022的内存视角中有三列数据,第三列是把第二列的 16 进制数据转换成对应的 ASCII 字符(无法映射的字符用./?表示),不想管可以先不管。
实际的内存模型只包含前面两列数据,内存地址和内存数据,一个内存单元占一个字节,下图第一列显示的都是多个连续的内存单元的起始地址,第二列显示的是连续存储的数据。
地址的二进制位数(宽度)直接决定了能表示的最大地址数量,进而决定了可访问的内存空间总大小
32 位地址(32 位 CPU / 操作系统)总内存空间:2^32 字节 = 4GB(理论上限)
64 位地址(当前主流 CPU / 操作系统)总内存空间:2^64 字节 = 16EB(理论上限)
现目前的CPU只实现了 48 位地址线:2^48 字节 = 256TB (硬件上限)
我们平常使用的电脑内存只有十几GB,主要是内存条贵和够用多方面原因。
第三章_基础语法
3.1 空白字符
空白字符有三种:空格,制表符,换行。空白字符不会影响代码的结构,只是起到一个分隔的作用,即使你写成下图这样,在C语言中也能够进行编译。
3.2 注释
行注释:// //这是一行注释
段注释:/**/ /*这是一\n段注释*/
3.3 关键字和标识符
关键字:诸如 int return 等32个,为C语言定义好的,不能把这些当做标识符,大小写敏感
标识符:以数字,下划线,字母组成(不能以数字开头,不能和关键字重复,大小写敏感),用于标识你自己定义的变量等,比如 Int,Return,_int 等。
第四章_常量,变量和数据类型
4.1 字面值常量
4.1.1 定义
字面型常量 = 程序中直接写出来、值不会改变的量,写出来就知道是什么意思。
- 数字: 10 / 3.14
- 字符: ‘a’
- 字符串: “abc”
- 布尔: true/false
4.1.2 默认类型变换
- 整数字面量(如 10、123):int –> unsigned int –> long long
- 浮点字面量(如 1.2、3.14):double
- 字符字面量(‘A’、‘1’): int(虽然通常存进的是 char,但字符常量本身是 int)
- 字符串字面量(“abc”): 默认类型:char[长度+1]
4.2 符号常量
4.2.1 定义
符号常量 = 用名字代表一个固定不变的值,避免魔法数字,主要依靠宏定义实现
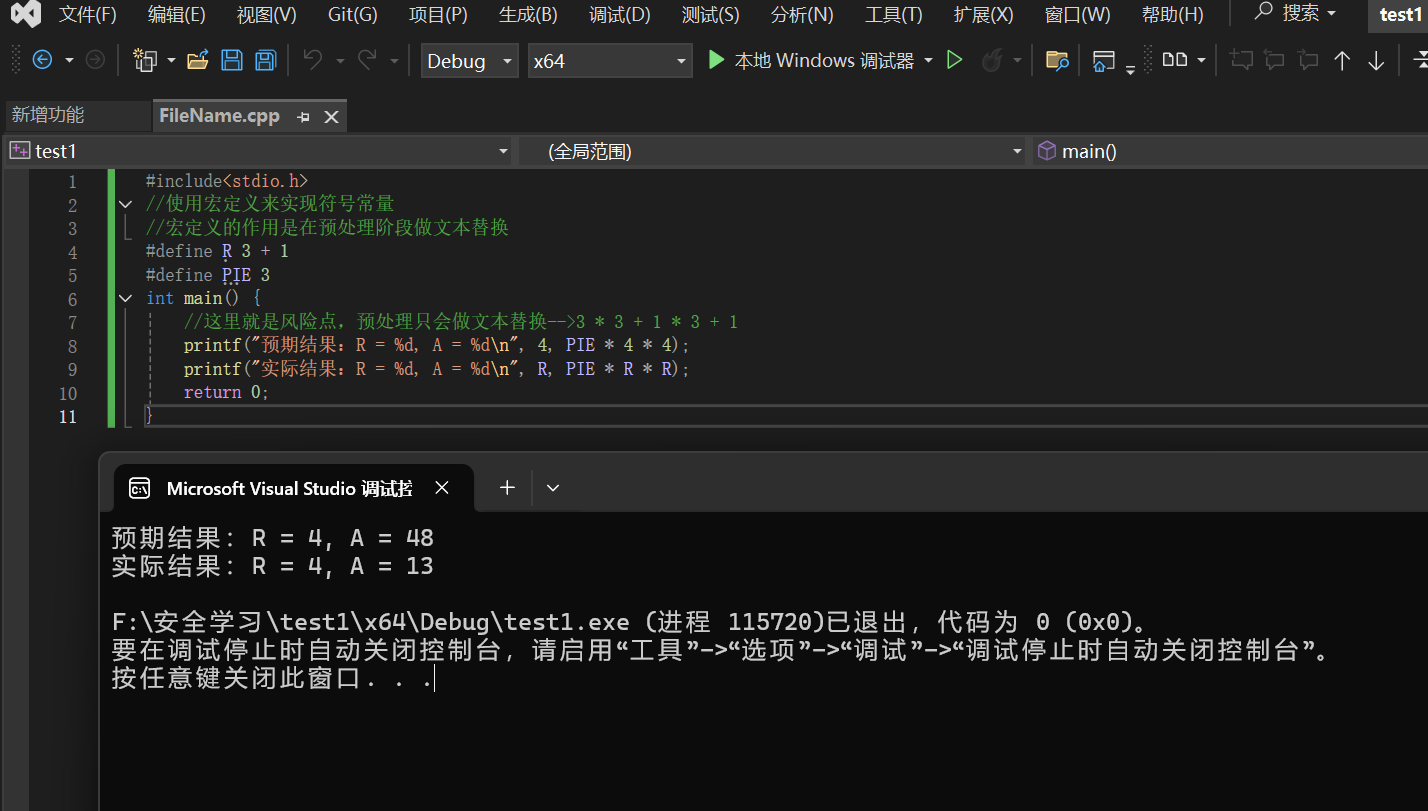
4.2.2 预处理
这里简单理解一下就行:
- 把宏定义的符号常量全部替换进入代码
- 去掉所有注释
- 流程:.cpp文件 –(预处理)–> .i文件 –> .exe文件
预处理这里存在风险:预处理只会做简单的文本替换,如下图所示:
4.3 变量的概念,定义和初始化
4.3.1 定义
变量 = 是内存中一块有名字的存储空间,用于存储程序运行过程中可以改变的数据
4.3.2 变量的初始化和赋值
- 赋值:用新的值去代替内存里原本的内容
- 初始化:在创建变量的时候就赋予一个初始值
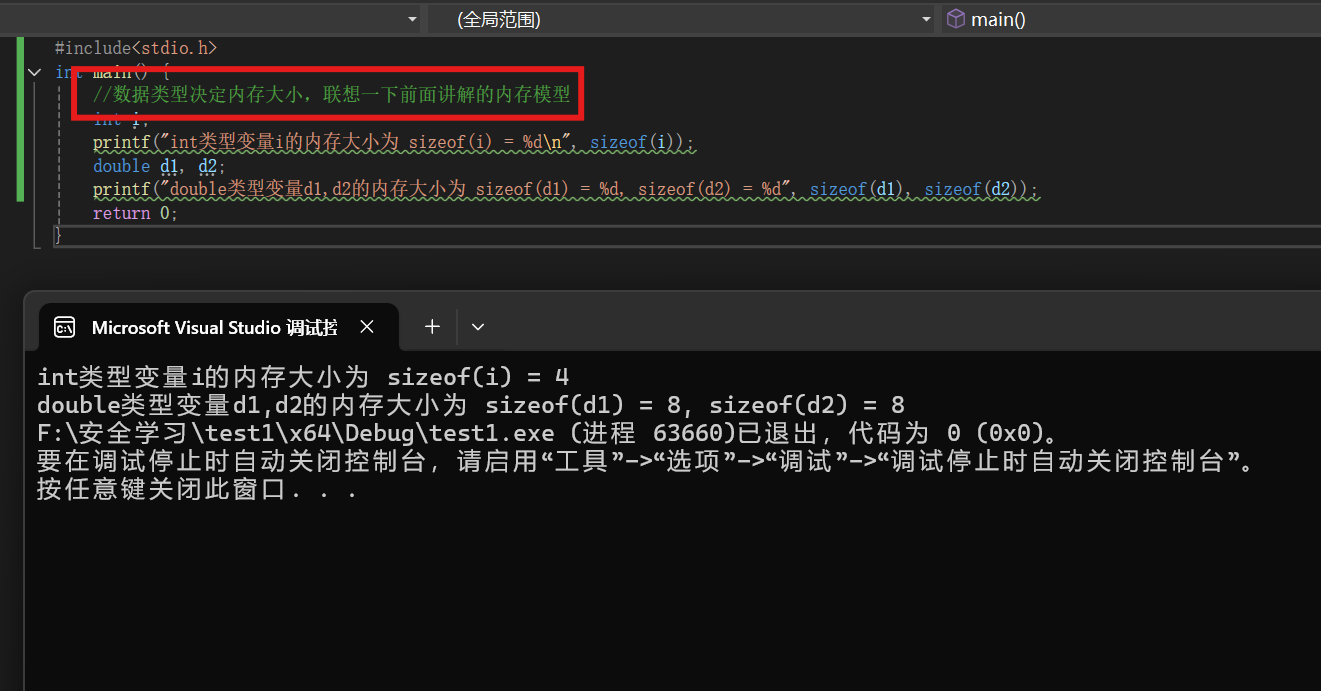
4.4 数据类型概览
整数
有符号整数
char 同时也是字符类型(在C语言中,字符的本质是整数)
short
int
long /long long
无符号整数 unsigned + 上面的有符号整数
浮点数
单精度 float
双精度浮点数 double
这里要注意的就是不同数据类型的内存占比大小(在不同平台上面的 int 和 long 会发生变化) 通常是:
1字节:char / unsigned char
↓
2字节:short / unsigned short
↓
4字节:int / unsigned int、float
↓
8字节:long / unsigned long、long long / unsigned long long、double
4.4.1 整数
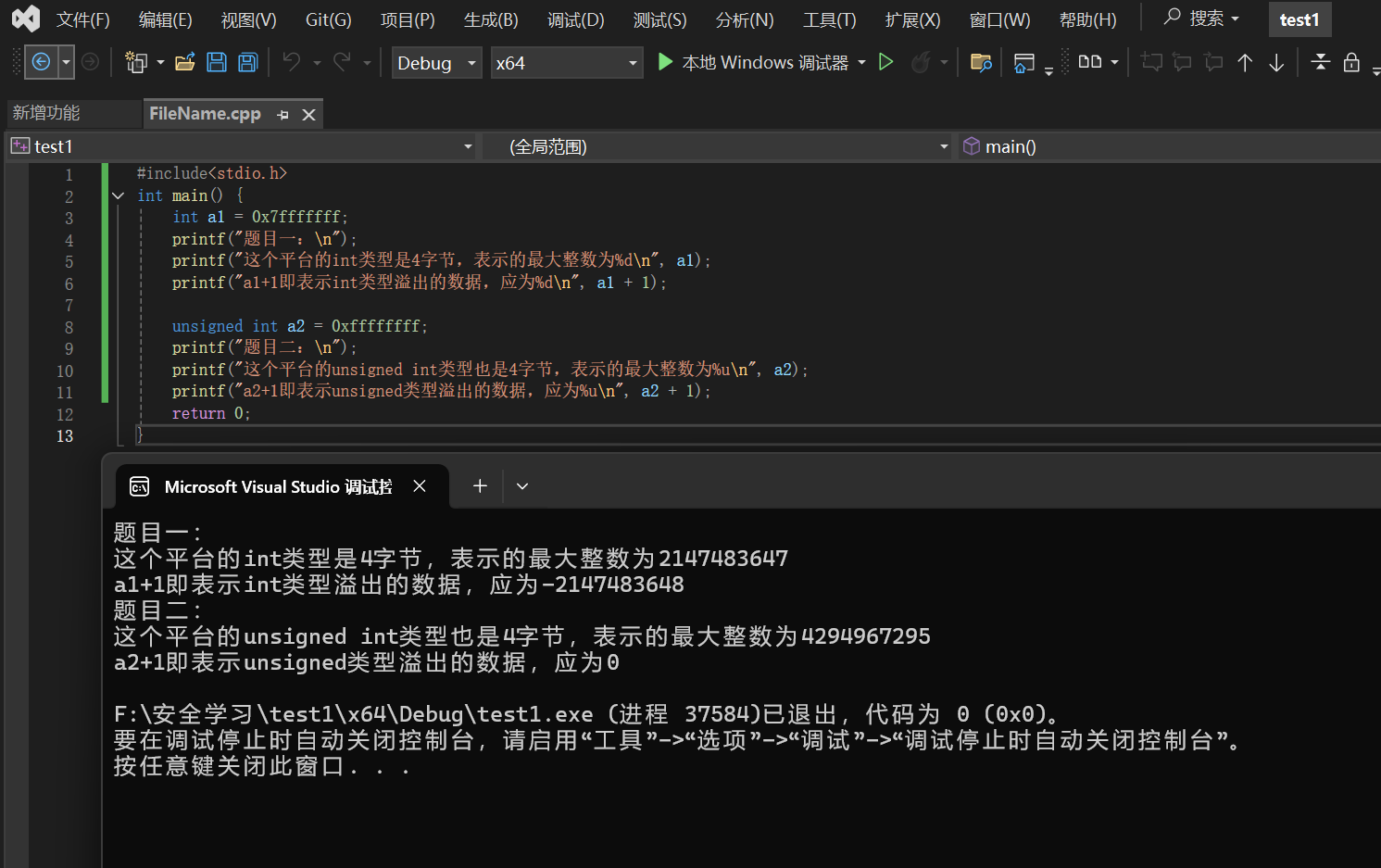
有无符号整数数据类型的数据表示范围及原因:不同整数数据类型表示的范围不一样,有些冗杂,容易记混,其实不用记,按位权理解即可:
- 有符号数的最高位是负权位:一个8位的有符号数,0111 1111 那自然表示的最大正值是 27- 1
- 无符号数的最高位是正权位,所有位都用来表示数值:一个8位的无符号数,1111 1111 那自然表示的是最大正值是 28 - 1
那其实同理,我们理解了这个上述位权,还能够准确理解溢出现象,如图所示
4.4.2 浮点数
double和float精度对比如下图所示:
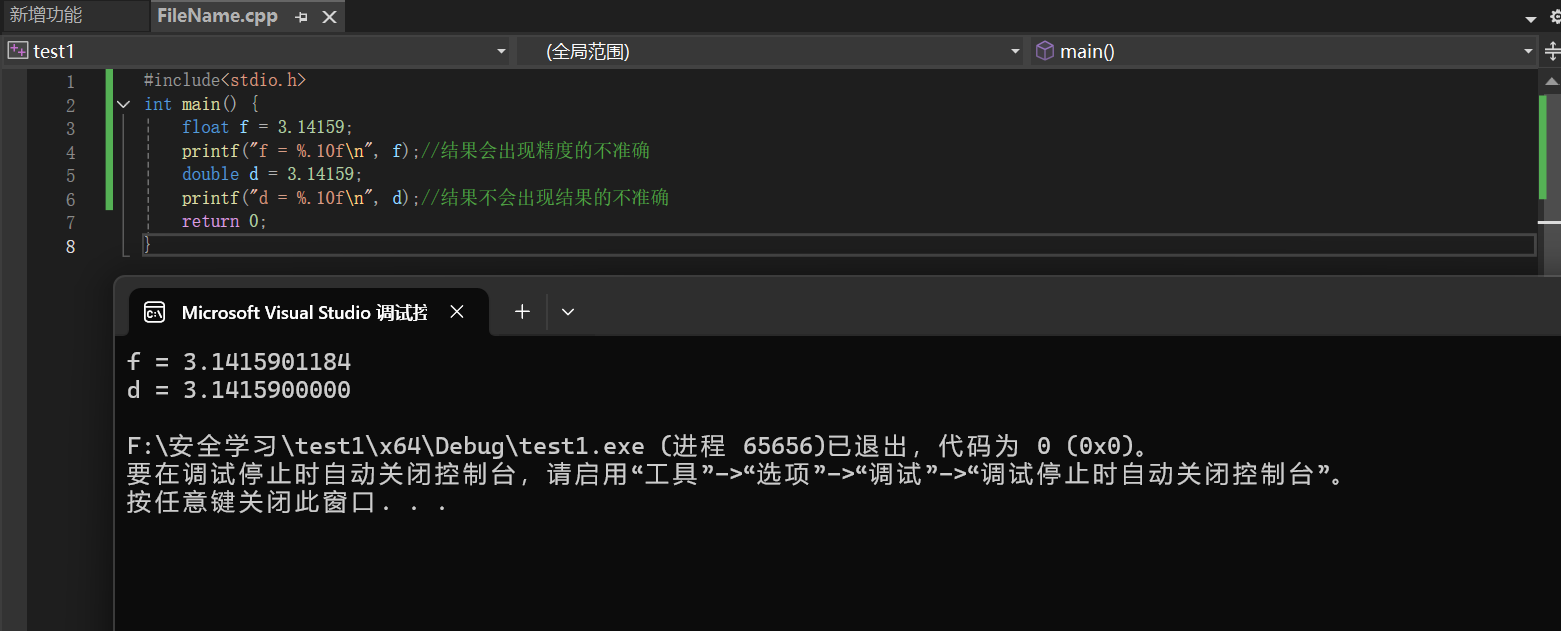
- double的精度比float高
- double的有效数字是15位
- float的有效数字是6位,比如3.14159是6位
浮点数精度丢失问题: C 语言的浮点数并不是十进制,而是二进制近似值,所以很多十进制小数不能被精确表达,从而出现误差、比较失败、累加不准等问题。
- 所以比较浮点数不能用 ==,以下几乎永远不成立:
if (0.1 + 0.2 == 0.3) - 正确比较方式是“允许一定误差”:
double a = 0.1 + 0.2; double b = 0.3; double eps = 1e-9; // 误差容忍值(10的-9次方) if (fabs(a - b) < eps) { printf("equal\n"); }
4.4.3 字符类型
char 是一个 1 字节的整数类型,本质上就是 0~255 的数字(unsigned 时),但存储时存的是 对应的 ASCII 数值
字符串是字符数组 + 结尾 ‘\0’:
char s[] = "ABC"; //真实存储:A B C \0
各种转义字符也要会使用,代码如下,请自行尝试
#include <stdio.h>
int main() {
char ch;
//ch = 'a';
//ch = '0';
//ch = ',';
// 转义字符
//ch = '\n';
//ch = '\r';
//ch = '\b';
//ch = '\t';
//ch = '\\';
printf("abc%cxyz", ch);
return 0;
}
第五章_输入和输出
5.1 缓冲区
缓冲区可以简单理解为内存中的一块区域,因为 CPU 运算速度很快,而键盘、磁盘、屏幕的速度都比它慢很多,如果每一次读写都直接等待设备响应,会让程序非常慢。所以系统会先把数据放到缓冲区里,等到条件合适再一起处理,这样效率会高很多。
需要了解的缓冲区(行为像队列):
- stdin : 标准输入缓冲区 –> scanf getchar fgets
- stdout : 标准输出缓冲区 –> printf gets
5.2 scanf函数
格式化输入,从标准输入拷贝数据到自己的内存,用法和流程如下:
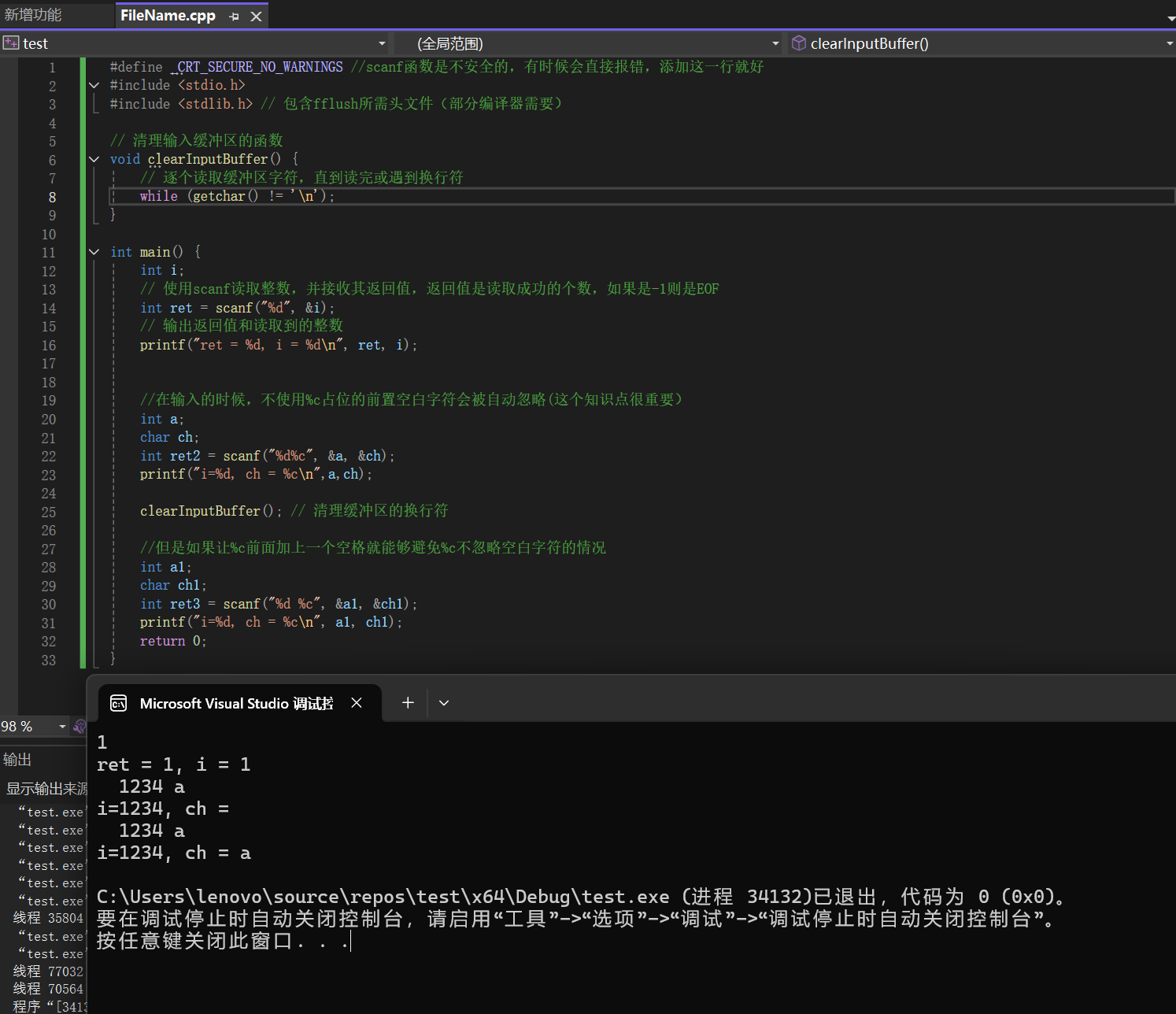 从键盘输入的数据被像队列一样一个一个被 stdin 缓冲区读取,再根据 scanf 输入的地址进行寻址写入:
从键盘输入的数据被像队列一样一个一个被 stdin 缓冲区读取,再根据 scanf 输入的地址进行寻址写入:
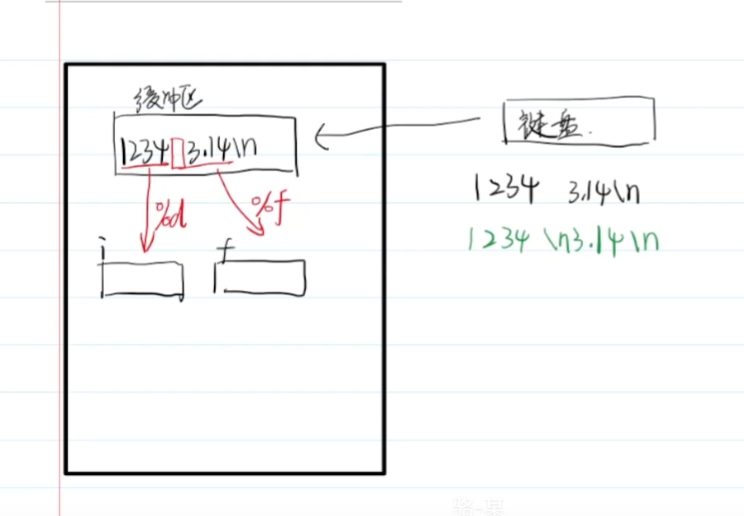
5.3 getchar函数
当你调用 getchar() 时,它会把缓冲区队头的字符取出来并返回,取出来后,队头自动移动到下一个字符
5.3.1 对比概述
getchar():
- 从 stdin 取 1 个字符
- 返回该字符的 ASCII 值
- 不会打印东西
scanf("%c"):
- 从 stdin 取 1 个字符
- 存入变量 ch
- 返回成功项数(1 或 0)
- 也不会打印
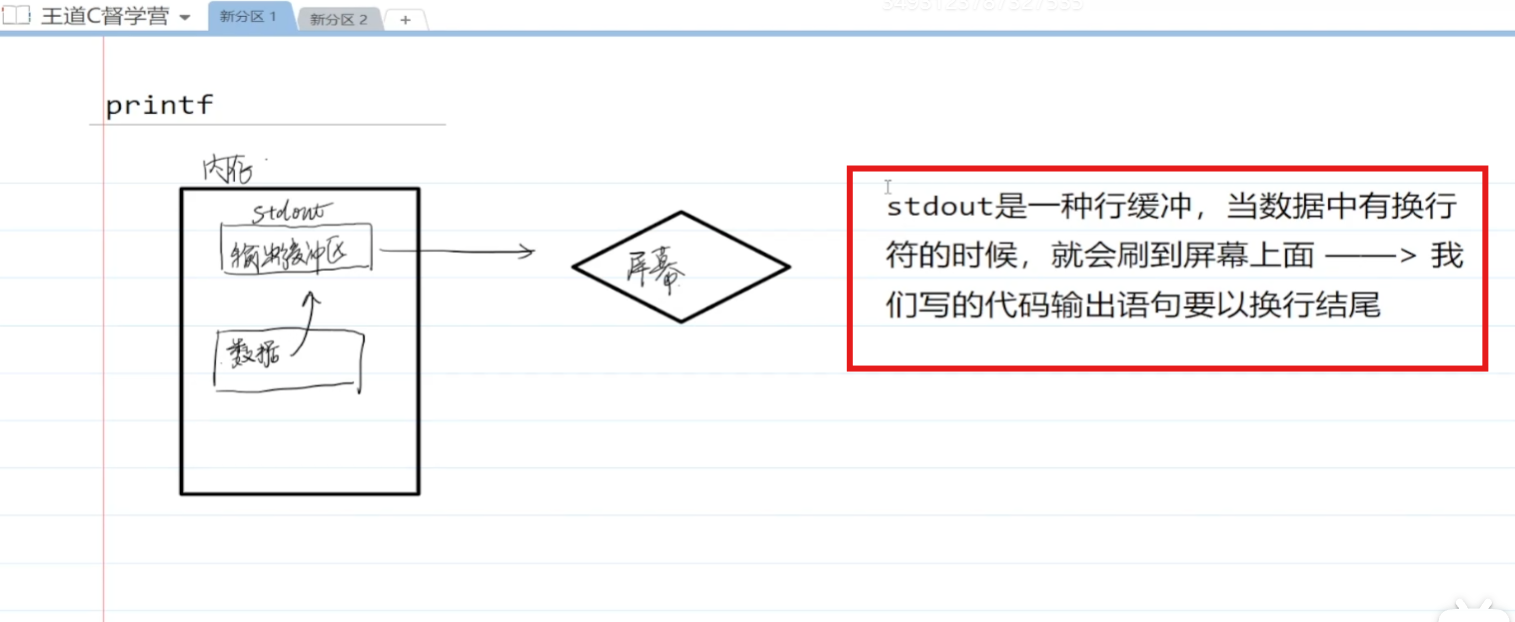
5.4 printf函数
格式化输出,把内容写入 stdout 缓冲区,系统再把它刷新到屏幕,用法和流程如下:
 VS 调试环境会自动刷新输出,所以C语言没写 \n 也能看到。
但直接运行编译过后的 exe 时,如果是行缓冲模式,没有 \n 可能不会立即显示。
VS 调试环境会自动刷新输出,所以C语言没写 \n 也能看到。
但直接运行编译过后的 exe 时,如果是行缓冲模式,没有 \n 可能不会立即显示。
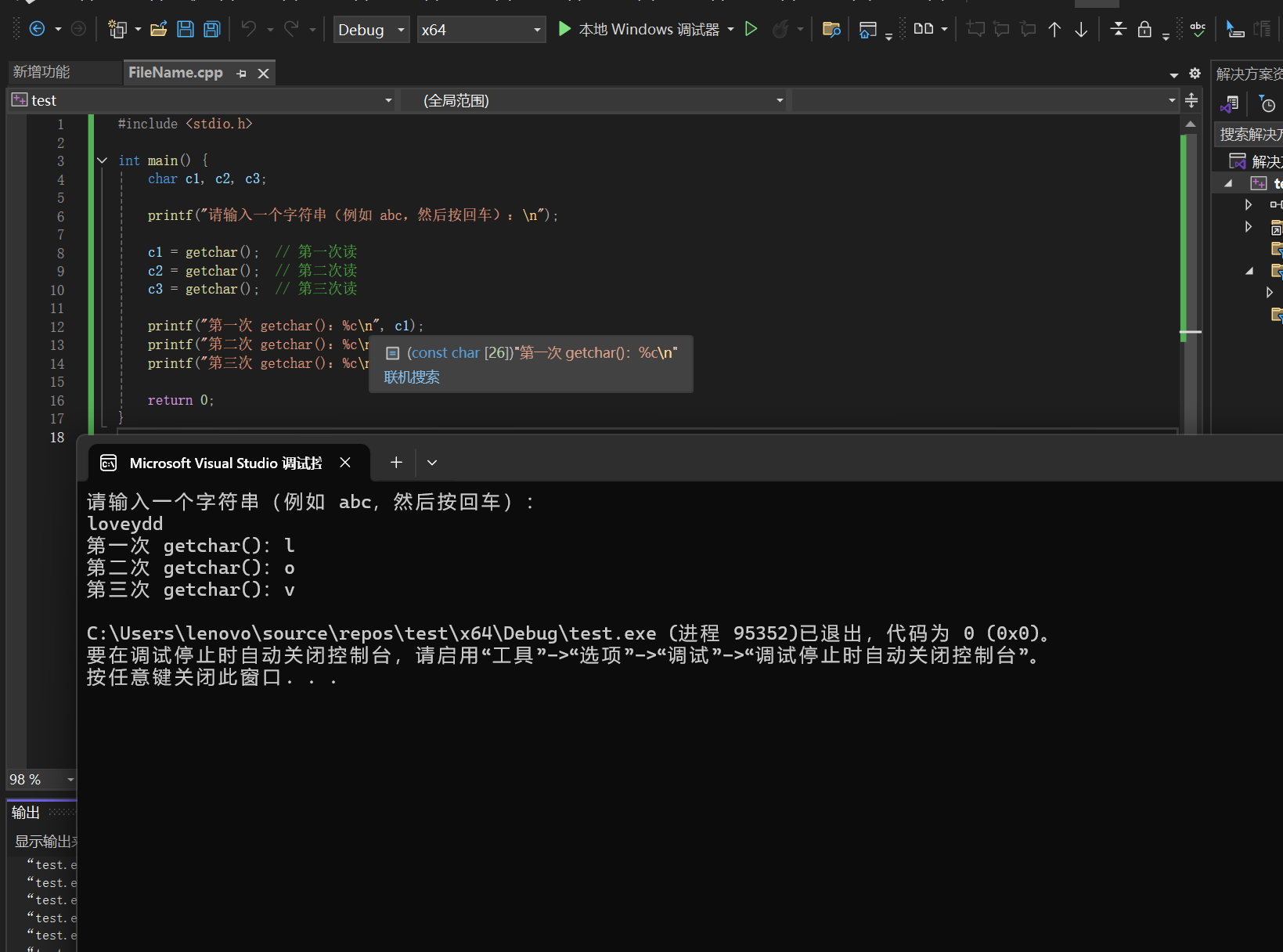
5.4.1 宽度设置
printf 中,格式控制符(如%d/%s)与%之间添加整数,可设置输出的最小宽度:
- 默认右对齐:若数据长度不足设置的宽度,会自动补空格;
- 加负号(如%-8s):实现左对齐;
- 加零号(如%03d):若整数长度不足宽度,用0填充(仅对数值类型有效)。
浮点数的特殊设置: 浮点数(对应格式符%f/%lf)除了 “最小宽度”,还可额外设置小数位数(格式为%[宽度].[小数位数]f),示例:
- %6.2f:总宽度至少 6(含小数点),保留 2 位小数;
- 若小数位数超出原数精度,会自动四舍五入;
- 零号填充(如%06.2f):不足总宽度时,整数部分前补0(而非空格)。
第六章_运算符和表达式
下面我会按照重要类型运算符优先级顺序从高到低进行介绍
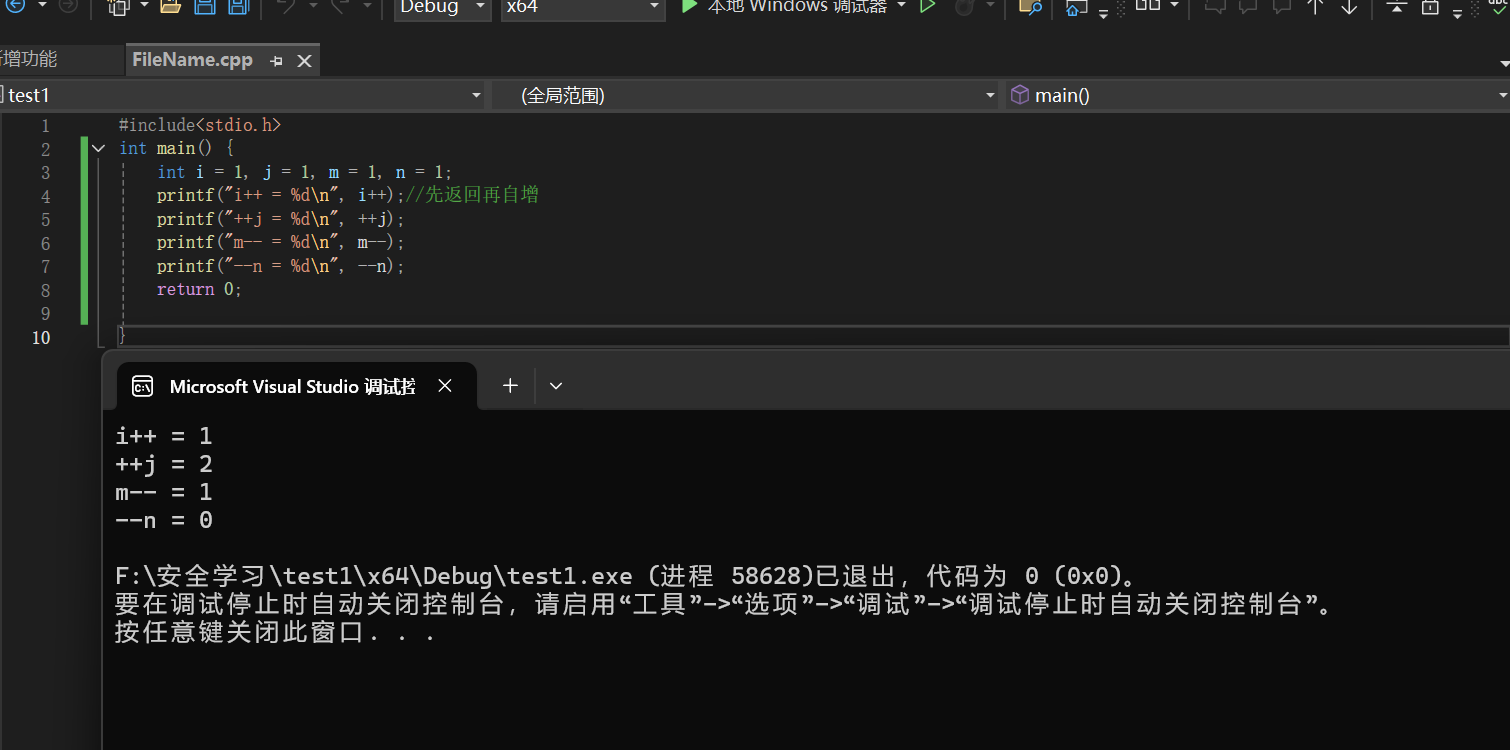
6.1 自增自减运算符和逻辑非
混淆点: 虽然 ++ 和 ! 是同级别且右结合,但 ! 是 “单目运算符”,需要一个运算对象,而 ++i 是一个完整的表达式(结果是一个值),所以 ! 只能作用于 ++i 的结果,而非反过来。
- ++!i:编译报错!因为 !i 的结果是 0/1(常量),自增自减运算符只能作用于变量,不能作用于常量;
- !i++:先取值 i 做 ! 运算,再执行 i++(后置自增)。比如 i=1 时,!i++ 先算 !1=0,再 i=2,最终结果是 0。
自增自减运算符前缀后缀的区别注意,运算规则和注意事项如下图所示
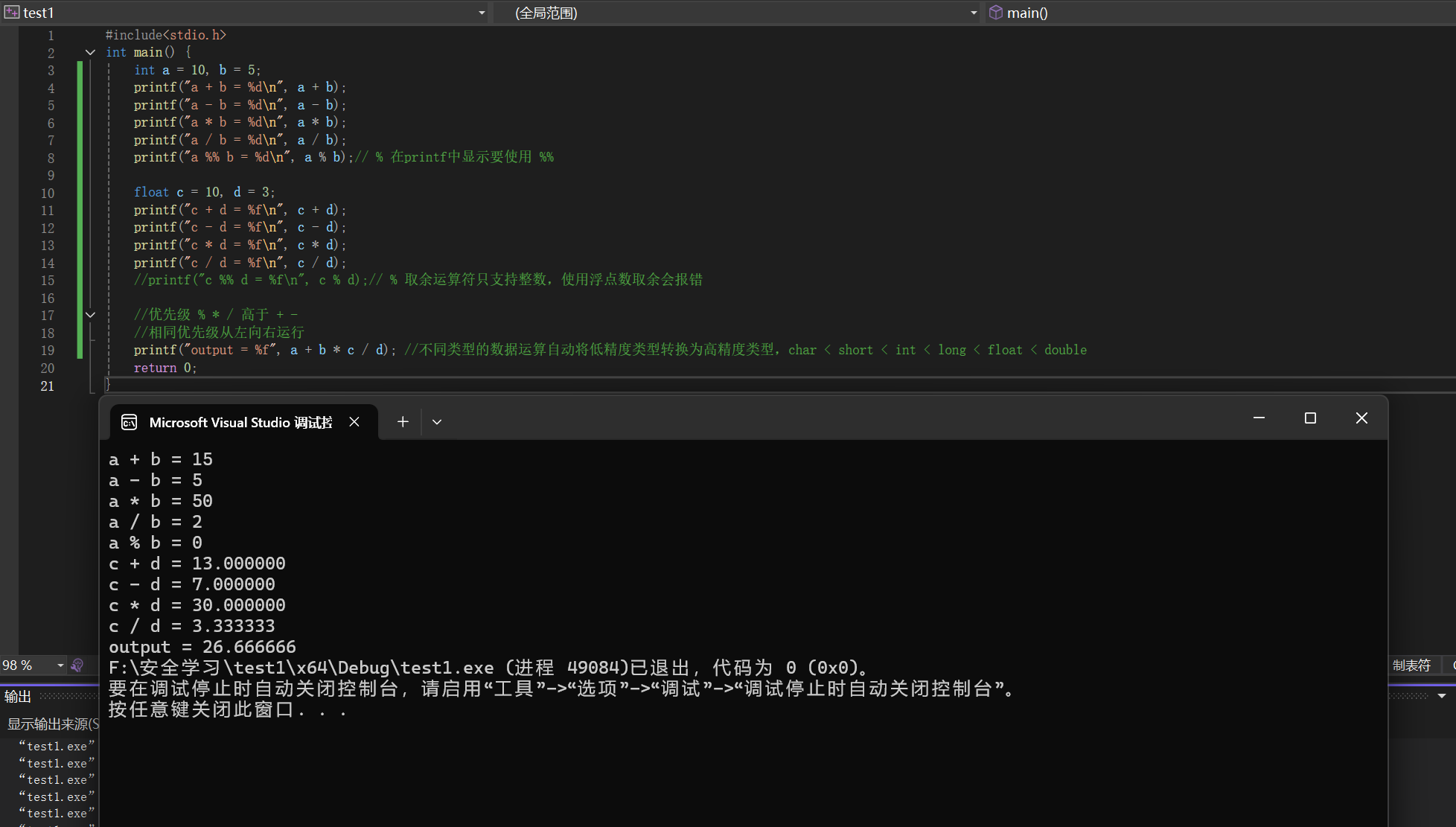
6.2 算术运算符
+ - * / %
内部优先级: * / % 优先级高于 + -
运算规则和注意事项如下图所示
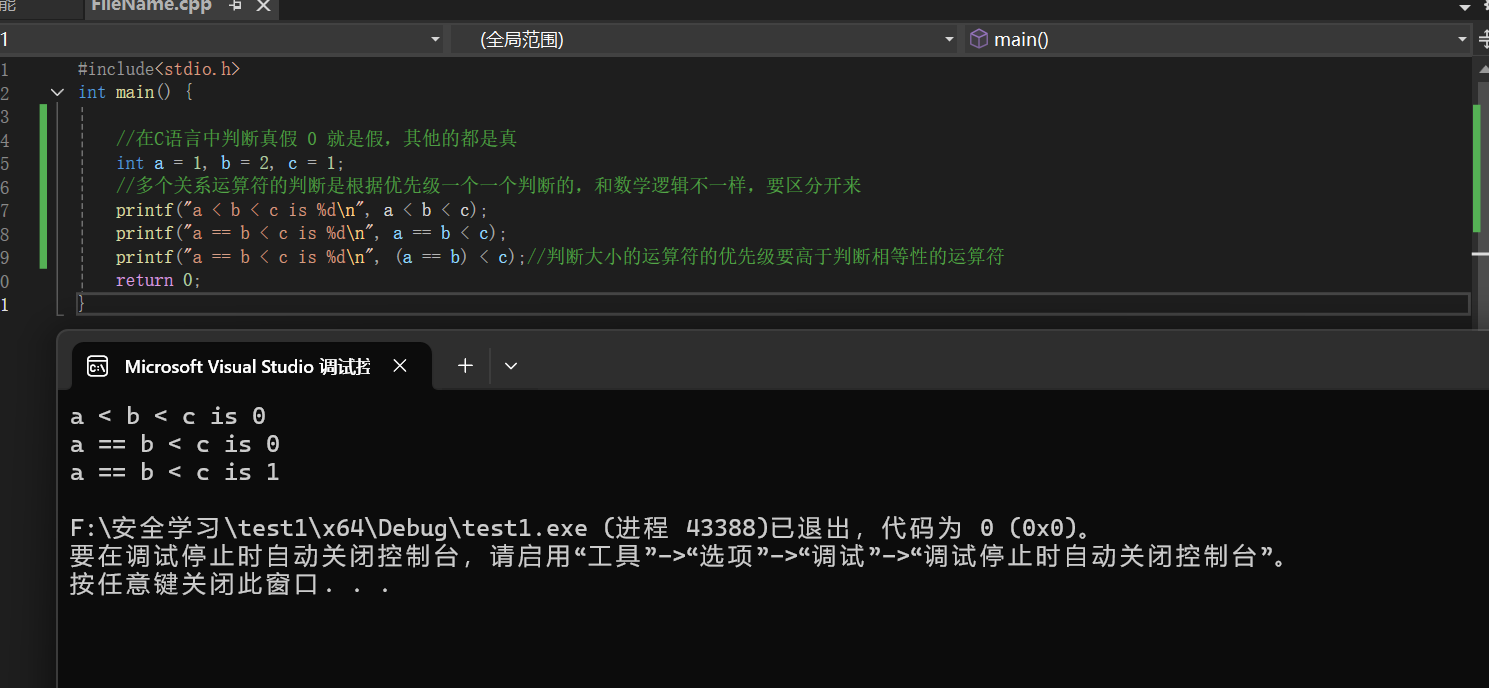
6.3 关系运算符
== != > < <= >=
内部优先级: 判断大小的运算符的优先级(<= >= < >)高于判断相等性的运算符的优先级(== !=)
运算规则和注意事项如下图所示
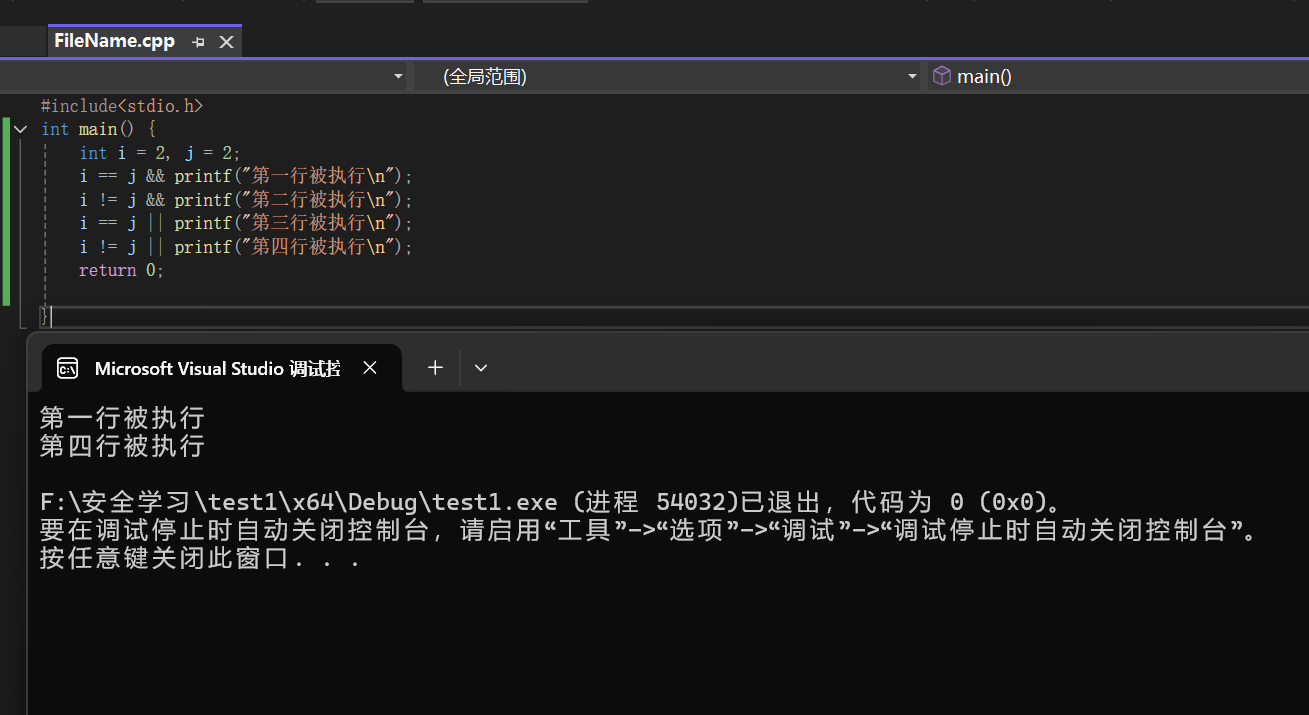
6.4 逻辑运算符
&& || !
内部优先级: !高于 && 高于 || ( ! 运算符在外部属于最高级别) 和关系运算符的返回值无区别,为真(非0)和假(0),用途有区别。
短路操作: 当表达式中出现 && || 一定是先做左边的操作,看是否触发短路操作,如果触发了短路操作就不会进行右边的操作,具体的操作如下图所示
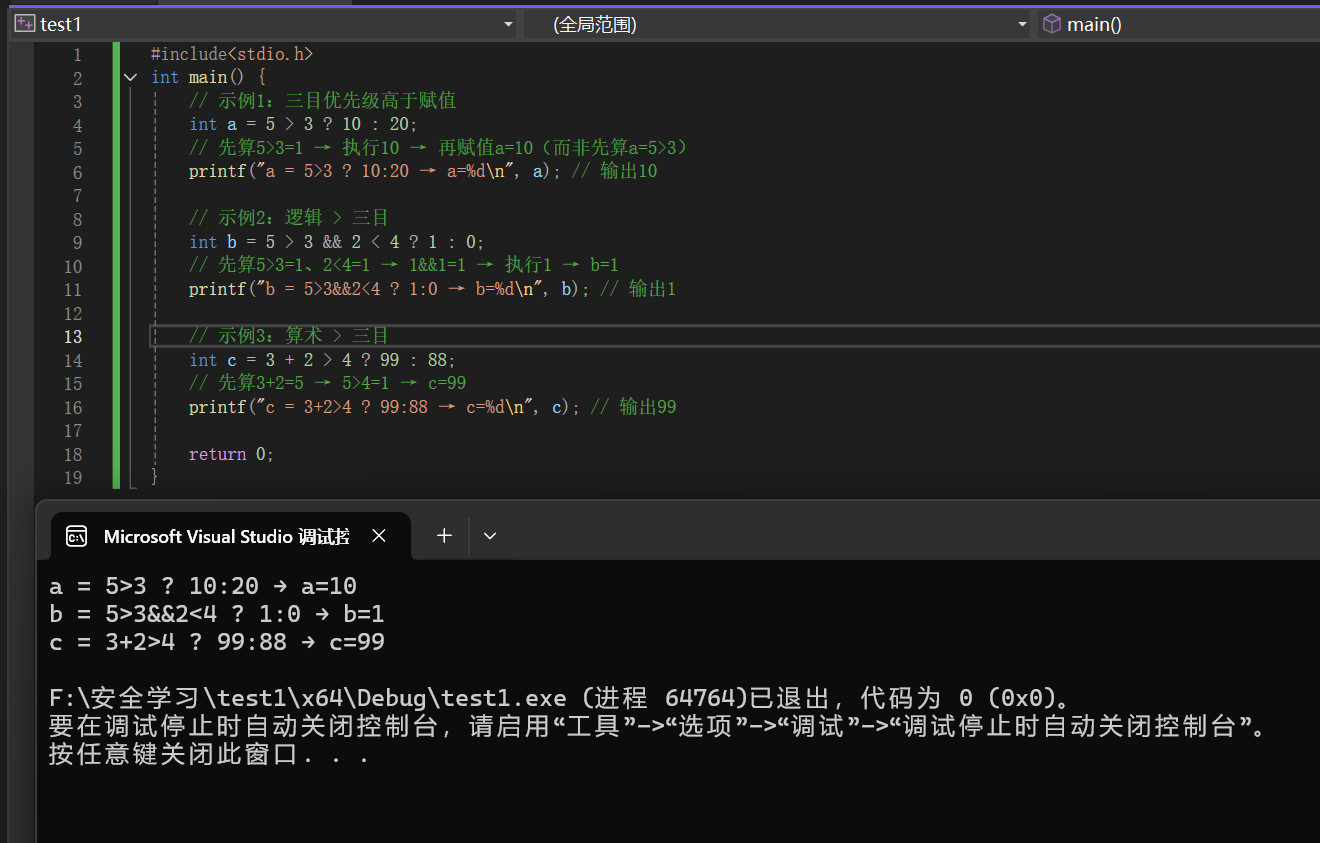
6.5 三目运算符
? :
运算规则和注意事项如下图所示
6.6 赋值运算符
运算规则和注意事项如下图所示
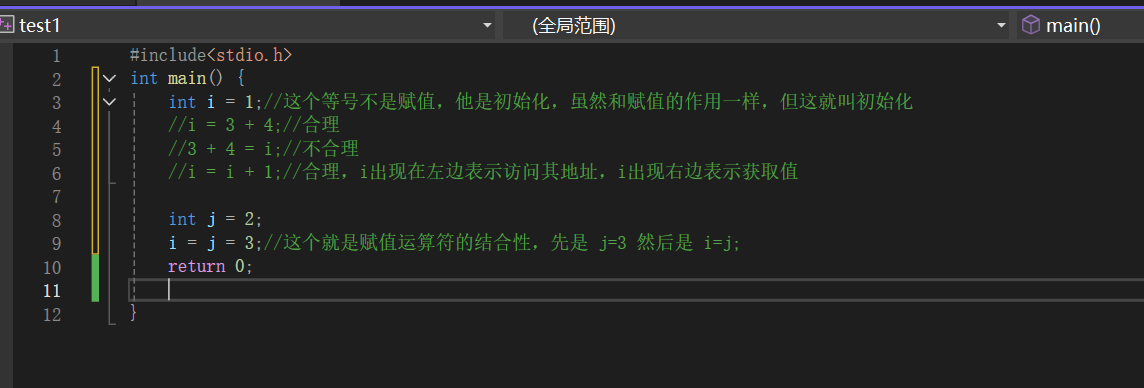
- 赋值运算符的左值:代表一片内存空间,且能够进行修改
- 赋值运算符的右值:数据就行
- 赋值运算的结合性:从右往左
6.7 逗号运算符
A,B –> 先执行A在执行B最后返回B,和 A;B; 很像
- if(i=i+1,i==2){} –> 使用场景:变量i,要求先改变i的值,再判断i是否合适。一般不会使用逗号运算符
- printf("%d",i); –> 这里的 , 不是逗号运算符
- while(scanf("%c",&ch),ch != ‘\n’) –> 执行的是前面scanf,返回的是后面的判断语句
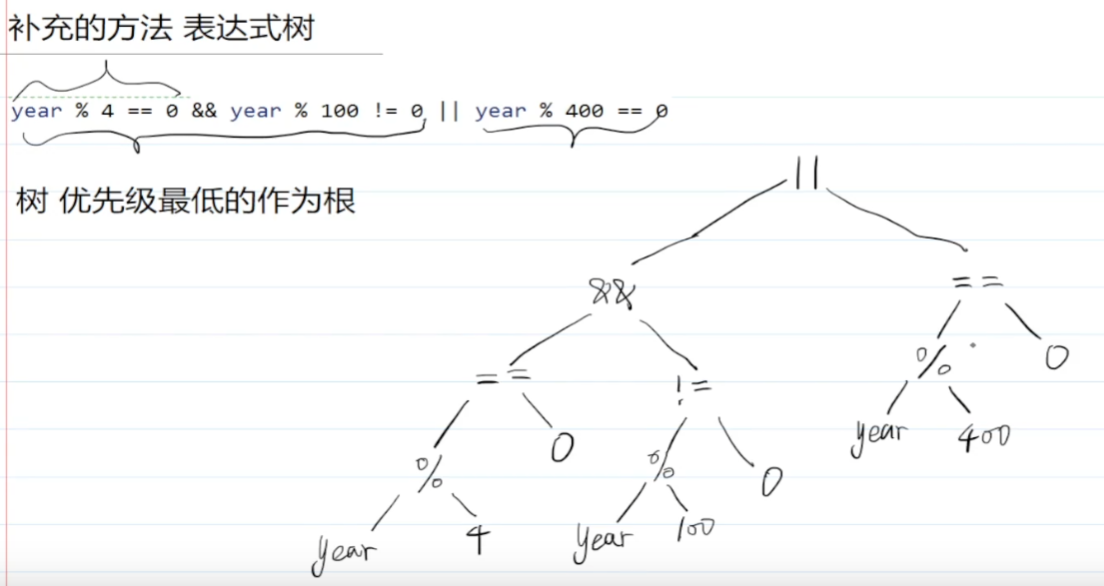
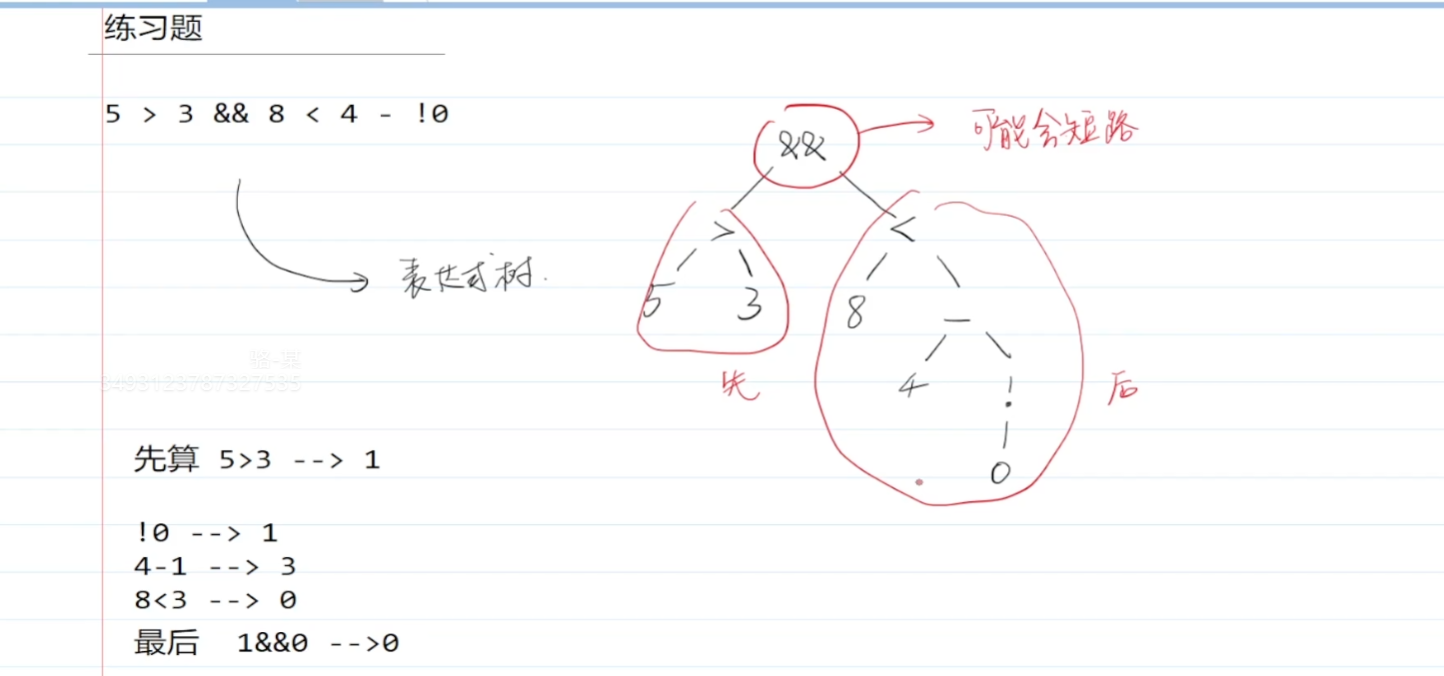
6.8 优先级和表达式树
对于复杂的表达式,可以采用下图这种方案来组织思路(越下面优先级越高,类似中序遍历)
附言
知识点看上去有些冗杂,很多知识点我在总结的过程中包含在图片里面,但是实际上对于有C语言基础的同学,看一遍基本就能回忆起来全部内容了,这些也全都是考研重点,有些遗忘的部分,可按照图中代码尝试一二。